To help bring the application of data science to a variety of fields, Case Western Reserve University has developed a unique Applied Data Science undergraduate minor that can be paired with any undergraduate major. The sequence launched in the fall of 2014.
This minor, based in the Case Western Reserve University School of Engineering, is open to all undergraduate majors: engineering, arts, sciences, nursing, and management. Students can choose from eight subdomains in which to concentrate their minor, all of which include a core curriculum that includes five 3-credit courses.
Domain areas available for minor concentration are:
- Engineering and Physical Sciences:
- Energy;
- Manufacturing; and
- Astronomy.
- Health:
- Translational; and
- Clinical.
- Business:
- Finance;
- Marketing; and
- Economics.
The pathway towards earning the Applied Data Science minor is organized into five levels:
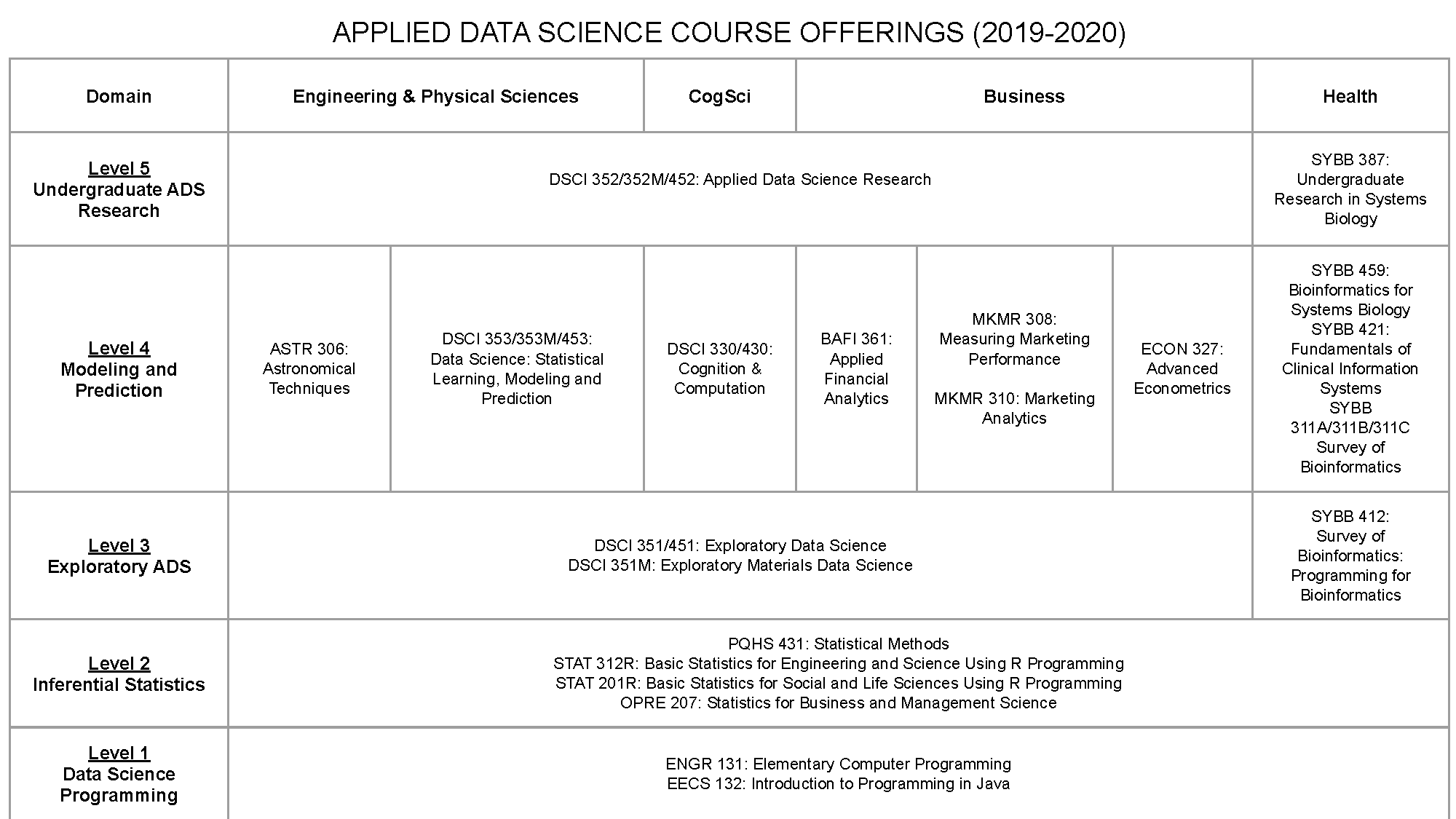
- ENGR 131: Elementary Computer Programming
- Students will learn the fundamentals of computer programming and algorithmic problem solving. Concepts are illustrated using a wide range of examples from engineering, science, and other disciplines. Students learn how to create, debug, and test computer programs, and how to develop algorithmic solution to problems and write programs that implement those solutions. Matlab is the primary programming language used in this course, but other languages may be introduced or used throughout. Counts for CAS Quantitative Reasoning Requirement.
- EECS 132: Introduction to Programming in Java
- Introduction to computer programming and problem solving with the Java language. Computers, operating systems, and Java applications; software development; conditional statements; loops; methods; arrays; classes and objects; object-oriented design; unit testing; strings and text I/O; inheritance and polymorphism; GUI components; application testing; abstract classes and interfaces; exception handling; files and streams; GUI event handling; generics; collections; threads; comparison of Java to C, C++, and C#. Counts for CAS Quantitative Reasoning Requirement.
- DSCI 133*: Introduction to Data Science and Engineering for Majors
- This course is an introduction to data science and analytics. In the first half of the course, students will develop a basic understanding of how to manipulate, analyze and visualize large data in a distributed computing environment, with an appreciation of open source development, security and privacy issues. Case studies and team project assignments in the second half of the course will be used to implement the ideas. Topics covered will include: Overview of large scale parallel and distributed (cloud) computing; file systems and file i/o; open source coding and distributed versioning, data query and retrieval; basic data analysis; visualization; data security, privacy and provenance. Prereq: ENGR 131 or EECS 132.
- DSCI 134*: Introduction to Applied Data Science
- This course is an introduction to data science and analytics. In the first half of the course, students will develop a basic understanding of how to manipulate, analyze and visualize large data in a distributed computing environment, with an appreciation of open source development, security and privacy issues. In the second half of the course, students will gain experience in data manipulation and analysis using scripted programming languages such as Python.
- OPRE 207: Statistics for Business and Management Science I (3)
- Organizing and summarizing data. Mean, variance, moments. Elementary probability, conditional probability. Commonly encountered distributions including binomial. Poisson, uniform, exponential, normal distributions. Central limit theorem. Sample quantities, empirical distributions. Reference distributions (chi-square, z-, t-, F-distributions). Point and interval estimation: hypothesis tests.
- Prerequisites: MATH 122 or MATH 126.
- PQHS 431: Statistical Methods in Biological and Medical Sciences I
- Application of statistical techniques with particular emphasis on problems in the biomedical sciences. Basic probability theory, random variables, and distribution functions. Point and interval estimation, regression, and correlation. Problems whose solution involves using packaged statistical programs. First part of year-long sequence. Offered as ANAT 431, BIOL 431, CRSP 431, PQHS 431 and MPHP 431.
- STAT 201R (taught using R statistics software): Basic Statistics for Social and Life Sciences (3)
- Designed for undergraduates in the social sciences and life sciences who need to use statistical techniques in their fields. Descriptive statistics, probability models, sampling distributions. Point and confidence interval estimation, hypothesis testing. Elementary regression and analysis of variance.
- Not for credit toward major or minor in Statistics. Counts for CAS Quantitative Reasoning Requirement.
- STAT 312R (taught using R statistics software): Basic Statistics for Engineering and Science (3)
- For advanced undergraduate students in engineering, physical sciences, life sciences. Comprehensive introduction to probability models and statistical methods of analyzing data with the object of formulating statistical models and choosing appropriate methods for inference from experimental and observational data and for testing the model’s validity. Balanced approach with equal emphasis on probability, fundamental concepts of statistics, point and interval estimation, hypothesis testing, analysis of variance, design of experiments, and regression modeling.
- Note: Credit given for only one (1) of STAT 312, 313, 333, 433.
- Prerequisites: MATH 122 or equivalent.
Engineering & Physical Sciences, Health and Business (All Domain areas)
- DSCI 351: Exploratory Data Science for Energy & Manufacturing
- Course Description: Data Sources, Data Assembly, and Exploratory Data Analytics. In this course, we will learn data science and analysis approaches applicable to energy and manufacturing technologies, to identify statistically significant relationships and better model and predict the behavior of these systems. We will assemble and explore real-world datasets, perform clustering and pair plot analysis to investigate correlations, and logistic regression will be employed to develop associated predictive models. Results will be interpreted, visualized and discussed.
We will introduce the basic elements of data science and analytics using R Project for Statistical Computing. R is an open-source software project with broad abilities to access machine-readable open data resources, data cleaning and munging functions, and a rich selection of statistical packages, used for data analytics, model development, and prediction. This will include an introduction to R data types, reading and writing data, looping, plotting and regular expressions so that one can start performing variable transformations for linear fitting and developing structural equation models while exploring for statistically significant relationships.
R Analytics will be applied to the case of energy systems (such as PV power plant degradation, and building energy efficiency) over time, by analyzing system responses, combined with results of experiments to identify fundamental principles that are statistically significant in the observed system performance. And it will be applied to manufacturing systems to understand the principles of statistical process control and identify critical factors of variability and uniformity. - Learning Outcomes:
- Familiarity with R Statistics, scripting, functions, packages, automated data analysis.
- Familiarity with exploratory data analysis, statistical model building
- Applications of domain knowledge and statistical analytics to identify important predictors and develop initial predictive models
- Dataset characteristics will include:
- Variety of types of information, including both, structured and unstructured data,
- Volume: Data from human sources (vendors, suppliers, distributors, customers, etc.) and sensor networks of the energy system of the factory, both small and large data volumes.
- Velocity: Energy system and manufacturing supply chain changes will be included.
- Course Description: Data Sources, Data Assembly, and Exploratory Data Analytics. In this course, we will learn data science and analysis approaches applicable to energy and manufacturing technologies, to identify statistically significant relationships and better model and predict the behavior of these systems. We will assemble and explore real-world datasets, perform clustering and pair plot analysis to investigate correlations, and logistic regression will be employed to develop associated predictive models. Results will be interpreted, visualized and discussed.
- SYBB 412 Survey of Bioinformatics: Programming for Bioinformatics
- SYBB 412 is a 3 credit-course that will introduce students to bioinformatics analysis and basic programming. This course is designed for those with little or no prior programming experience. However, advanced programmers can still learn bioinformatics pipelines and software packages to conduct research. Students will gain hands-on experience working with bioinformatics software, R packages and functions designed for bioinformatics applications. Programming for Bioinformatics course mainly focuses on R (rproject.org), and introduces students to basic programming in R, what packages are available, and teaches an introductory hands-on experience working with R by walking through the students in analyzing large -omics datasets. At the end of the class, the students are assessed with a small-scale project, where they analyze a publicly available dataset and produce a short report. This is an active learning class where adaptive learning and active learning teaching practices are used. Adaptive learning provide personalized learning, where efficient, effective, and customized learning paths to engage each student is offered. Recommended Preparation: BIOL 326 (Genetics) or equivalent Prereq: (SYBB 411A and Graduate Standing) or Requisites Not Met Permission.
Engineering and Physical Sciences
- ASTR 306: Astronomical Techniques
- This course covers the techniques astronomers use to conduct research, including observations using ground-and space-based telescopes, computer simulations and other numerical methods, and statistical data mining of large on-line astronomical datasets. Offered as ASTR 306 and ASTR 406. Counts as SAGES Departmental Seminar. Prereq: ASTR 222.
- DSCI 353: Data Science: Statistical Learning, Modeling and Prediction
- In this course, we will use an open data science tool chain to develop reproducible data analyses useful for inference, modeling and prediction of the behavior of complex systems. In addition to the standard data cleaning, assembly and exploratory data analysis steps essential to all data analyses, we will identify statistically significant relationships from datasets derived from population samples, and infer the reliability of these findings. We will use regression methods to model a number of both real-world and lab-based systems producing predictive models applicable in comparable populations. We will assemble and explore real-world datasets, use pair-wise plots to explore correlations, perform clustering, self-similarity, and logistic regression develop both fixed-effect and mixed-effect predictive models. We will introduce machine-learning approaches for classification and tree-based methods. Results will be interpreted, visualized and discussed. We will introduce the basic elements of data science and analytics using R Project open source software. R is an open-source software project with broad abilities to access machine-readable open-data resources, data cleaning and assembly functions, and a rich selection of statistical packages, used for data analytics, model development, prediction, inference and clustering. For students with little prior R experience, we'll introduce resources to learn R data types, reading and writing data, looping, plotting and regular expressions. With this background, it becomes possible to start performing variable transformations for linear regression fitting and developing structural equation models, fixed-effects and mixed-effects models along with other statistical learning techniques, while exploring for statistically significant relationships. The class will be structured to have a balance of theory and practice. We'll split class into Foundation and Practicum a) Foundation: lectures, presentations, discussion b) Practicum: coding, demonstrations and hands-on data science work. Offered as DSCI 353, DSCI 353M and DSCI 453.
- DSCI 330/430 Cognition & Computation
- An introduction to (1) theories of the relationship between cognition and computation; (2) computational models of human cognition (e.g. models of decision-making or concept creation); and (3) computational tools for the study of human cognition. All three dimensions involve data science: theories are tested against archives of brain imaging data; models are derived from and tested against datasets of e.g., financial decisions (markets), legal rulings and findings (juries, judges, courts), legislative actions, and healthcare decisions; computational tools aggregate data and operate upon it analytically, for search, recognition, tagging, machine learning, statistical description, and hypothesis testing. Offered as COGS 330, COGS 430, DSCI 330 and DSCI 430.
Health
- SYBB 459 (Translational ADS)
- Description of omic data (biological sequences, gene expression, protein-protein interactions, protein-DNA interactions, protein expression, metabolomics, biological ontologies), regulatory network inference, topology of regulatory networks, computational inference of protein-protein interactions, protein interaction databases, topology of protein interaction networks, module and protein complex discovery, network alignment and mining, computational models for network evolution, network-based functional inference, metabolic pathway databases, topology of metabolic pathways, flux models for analysis of metabolic networks, network integration, inference of domain-domain interactions, signaling pathway inference from protein interaction networks, network models and algorithms for disease gene identification, identification of dysregulated subnetworks network-based disease classification. Offered as EECS 459 and SYBB 459.
- SYBB 421 Fundamentals of Clinical Information Systems
- Technology has played a significant role in the evolution of medical science and treatment. While we often think about progress in terms of the practical application of, say, imaging to the diagnosis and monitoring of disease, technology is increasingly expected to improve the organization and delivery of healthcare services, too. Information technology plays a key role in the transformation of administrative support systems (finance and administration), clinical information systems (information to support patient care), and decision support systems (managerial decision-making). This introductory graduate course provides the student with the opportunity to gain insight and situational experience with clinical information systems (CIS). Often considered synonymous with electronic medical records, the "art" of CIS more fundamentally examines the effective use of data and information technology to assist in the migration away from paper-based systems and improve organizational performance. In this course we examine clinical information systems in the context of (A) operational and strategic information needs, (B) information technology and analytic tools for workflow design, and (C) subsequent implementation of clinical information systems in patient care. Legal and ethical issues are explored. The student learns the process of "plan, design, implement" through hands-on applications to select CIS problems, while at the same time gaining insights and understanding of the impacts placed on patients and health care providers. Offered as EBME 473, IIME 473 and SYBB 421.
- SYBB 311/411 Survey of Bioinformatics
- SYBB 311A/411A is a 5-week course that introduces students to the high-throughput technologies used to collect data for bioinformatics research in the fields of genomics, proteomics, and metabolomics. In particular, we will focus on mass spectrometer-based proteomics, DNA and RNA sequencing, genotyping, protein microarrays, and mass spectrometry-based metabolomics. This is a lecture-based course that relies heavily on out-of-class readings. Graduate students will be expected to write a report and give an oral presentation at the end of the course. SYBB 311A/411A is part of the SYBB survey series which is composed of the following course sequence: (1) Technologies in Bioinformatics, (2) Data Integration in Bioinformatics, (3) Translational Bioinformatics, and (4) Programming for Bioinformatics. Each standalone section of this course series introduces students to an aspect of a bioinformatics project - from data collection (SYBB 311A/411A), to data integration (SYBB 311B/411B), to research applications (SYBB 311C/411C), with a fourth module (SYBB 311D/411D) introducing basic programming skills. Graduate students have the option of enrolling in all four courses or choosing the individual modules most relevant to their background and goals with the exception of SYBB 411D, which must be taken with SYBB 411A. Offered as SYBB 311A, BIOL 311A and SYBB 411A. Prereq: (BIOL 214 and BIOL 215) or BIOL 250. Coreq: SYBB 311B, SYBB 311C, and SYBB 311D.
Business
- BAFI 361 (Finance)
- This course is developed based on the feedback received from employers who have hired BS Management (finance) graduates in the past and will likely do so in future. The goal is to enable students to use financial econometrics to effectively analyze financial data. The course will draw on theoretical aspects of BAFI 355but focus on developing financial analytic skills. The applied nature of the course comes from the use of real, rather than theoretical, data. In other words, in a real-world fashion, through the use of statistical methods to analyze real data, the student can address practical questions of high relevance to the Finance industry. The scope of the data as well as the quantitative methods used in such analysis often requires familiarity with computational environments and statistical packages. As such, another goal of the course is to familiarize the student with at least one such environment. Prereq: BAFI 355 and STAT 207 or OPRE 207.
- MKMR 308 (Marketing)
- Evaluation and control are important strategic marketing processes and without effective and consistent measurement, these processes cannot be performed adequately. In recent years, marketing budgets have been challenged by top managers as the value of these expenditures to an organization's financial well being is not often clear. Marketing activities such as advertising, sales promotions, sales force allocation, new product development, and pricing all involve upfront investments and making these investments now require increasing scrutiny. This course will be about knowing and understanding what to measure, how to measure, and how to report it so the link between marketing tactics and financial outcomes is clearer. The course will include lecture by the instructor, readings, cases, computer based data exercises, and guest lectures. There will also be a team project requirement. Prereq: ACCT 101 or 203, ECON 102 and MKMR 201
- MKMR 310 (Marketing)
- To appreciate, design, and implement data-based marketing studies for extracting valid and useful insights for managerial action that yield attractive ROI, five essential processes are emphasized: (a) making observations about customers, competitors, and markets, (b) recognizing, formulating, and refining meaningful problems as opportunities for managerial action, (c) developing and specifying testable models of marketing phenomenon, (d) designing and implementing research designs for valid data, and (e) rigorous analysis for uncovering and testing patterns and mechanisms from marketing data. Prereq: MKMR 201 and OPRE 207.
- ECON 327 (Economics)
- This class builds on the foundations of applied regression analysis developed in ECON 326. The goal of the class is to equip students with the tools to conduct a causal analysis of a hypothesis in a variety of settings. Topics will include causality, panel and time series data, instrumental variables and quasi-experiments, semi- and non-parametric methods, and treatment evaluation. Offered as ECON 327 and ECON 427. Prereq: ECON 326.
Engineering & Physical Sciences, Health and Business (All Domain areas)
- DSCI 352: Applied Data Science Research
- This is a project based data science research class, in which project teams identify a research project under the guidance of a domain expert professor. The research is structured as a data analysis project including the 6 steps of developing a reproducible data science project, including 1: Define the ADS question, 2: Identify, locate, and/or generate the data 3: Exploratory data analysis 4: Statistical modeling and prediction 5: Synthesizing the results in the domain context 6: Creation of reproducible research, Including code, datasets, documentation and reports. During the course special topic lectures will include Ethics, Privacy, Openness, Security, Ethics. Value. The M section of DSCI 352 is for students focusing on Materials Data Science. Offered as DSCI 352, DSCI 352M and DSCI 452. Prereq: (DSCI 133 or DSCI 134 or ENGR 131 or EECS 132) and (STAT 312R or STAT 201R or SYBB 310 or PQHS/EPBI 431 or OPRE 207) and (DSCI 351 or (SYBB 311A and SYBB 311B and SYBB 311C and SYBB 311D) or SYBB 321 or MKMR 201).
- SYBB 387: Undergraduate Research in Systems Biology
- This course provides students research experience in data science, proteomics, bioinformatics, and clinical informatics under the guidance of faculty affiliated with the Systems Biology and Bioinformatics program. Areas of research include production of big data at bench (cellular proteomics, structural proteomics, genomics, and interaction proteomics) and analysis of big data such as computational/statistical biology, bioinformatics tool development and clinical research informatics. A written report must be approved by the sponsor and submitted to the director of the Center for Proteomics and Bioinformatics before credit is granted.
Harnessing the resources of faculty expertise in materials science, electrical engineering and computer science, mechanical and aerospace engineering, systems biology, design and innovation, economics, finance and astronomy, the Applied Data Science minor teaches essential tools and applications within each domain area. This includes:
- data management: Datastores, sources, streams
- distributed computing: local and distributed computing (including Hadoop and other cloud computing)
- informatics, ontology, query: including search, data assembly and annotation
- statistical analytics: including tools such as high-level scripting languages such as R statistics, Python and Ruby
View a presentation on the making of the ADS program given to the Business Higher Education Forum: Crafting a Minor to Produce T-Shaped Graduates